Użytkownicy często mają pytania dotyczące tego, czym jest adres URL pliku (witryny), jak go znaleźć i jaka jest wartość takich szczegółów. Nasz artykuł dostarczy niezbędnych odpowiedzi.
Co to jest adres URL
Uniform Resource Locator oznacza „lokalizator lokalizacji witryny internetowej”. Identyfikator URL składa się z nazwy domeny i ścieżki do konkretnej strony z nazwą jej pliku. Wynalazcą adresu URL był Tim Berners-Lee, członek Europejskiej Rady ds. Wojny Jądrowej w Genewie. W momencie jej tworzenia w 1990 r. adres URL witryny był po prostu adresem w systemie, pod którym znajduje się plik. Aby znaleźć adres URL witryny, wystarczy spojrzeć na pasek adresu i określić adres pliku, do którego należy przejść menu kontekstowe klikając na odpowiedni obiekt prawy przycisk myszy. Mając wiele zalet, w szczególności dostępność nawigacji w sieci, taki adres ma również wadę - możliwość pracy wyłącznie z alfabetem łacińskim, niektórymi symbolami i cyframi. Jeśli konieczne jest użycie cyrylicy, przeprowadzana jest specjalna konwersja.
Rodzaje adresów URL
Statyczny – nie wiąże się ze zmianami na stronie.
Dynamiczny adres URL - co to jest, możesz zrozumieć, wyobrażając sobie formularz wyszukiwania lub inne narzędzie nawigacyjne, w którym generowane są informacje w zależności od przychodzących żądań.
Adres z identyfikatorem sesji dodawanym za każdym razem, gdy użytkownik odwiedza stronę.
Znaczenie adresu URL w promocji SEO
Wyszukiwarki biorą pod uwagę klucze zawarte w adresie URL. Największy wpływ na promocję w wyszukiwarkach mają słowa kluczowe w domenie i subdomenach.
Jeśli adres strony ma charakter informacyjny, zwiększa to również jej ranking. Szukaj robota najprawdopodobniej wyświetli go w odpowiedzi na aktualne zapytanie.
Adres URL pasujący do zapytania jest pogrubiony w wynikach wyszukiwania, przyciągając dodatkową uwagę i zwiększając współczynnik klikalności.
Zagubić się można nie tylko w lesie, ale także w Internecie. Może to być spowodowane niepoprawną ścieżką lub adresem prowadzącym do zasobu. Nie wiesz, co to jest adres URL? Następnie, zanim wyruszymy w dalszą podróż po wirtualnej przestrzeni, przyjrzyjmy się systemowi adresów e-mail.
Co to jest adres URL
Adres URL to ogólnie przyjęty standard zapisywania adresu i wskazywania lokalizacji zasobu w Internecie. Z angielskiego jego nazwa ( Jednolity lokalizator zasobów) jest tłumaczone jako ujednolicony lokalizator zasobów. Można znaleźć wcześniejsze dekodowanie skrótu URL — uniwersalny lokalizator zasobów (uniwersalny lokalizator zasobów). Jednak oba znaczenia uzupełniają koncepcję adresu URL, a nie sobie zaprzeczają.
Podstawowy format zapisu struktury Adres URL i wygląda to tak:
://:@:/?#
- najczęściej mamy na myśli protokół.
login – login użytkownika służący do autoryzacji na zasobie.
hasło – hasło użytkownika do autoryzacji.
Host – nazwa domeny hosta.
port – port hosta używany podczas połączenia.
Adres URL to ścieżka, w której żądany zasób znajduje się na serwerze.
parametry i kotwica– wartość zmiennych i identyfikator na konkretnym zasobie.
Przekazywanie wartości zmiennych w ciągu zapytania możliwe jest wyłącznie przy wykorzystaniu metody GET.
Przyjrzyjmy się formatowi adresu URL strony żądanego zasobu na praktycznych przykładach. Po stronie klienta adres URL jest wyświetlany w pasku adresu przeglądarki:
Najczęstsze opcje to:
- http://ru.wikipedia.org/wiki/Main_page– Do przesłania żądania używany jest protokół HTTP ( protokół przesyłania hipertekstu);
- https://ru.wikipedia.org/wiki/Strona_domowa— https jest używany jako metoda transmisji. Jest bezpieczną formą protokołu http wykorzystującą szyfrowanie (SSL lub TLS);
- fttp://wikipedia.org/wiki/file.txt– protokół przesyłania plików fttp;
- http://mail.ru/script.php?num=10&type=new&v=text– przekazywanie wartości zmiennych w ciągu zapytania metodą GET.
Każdy format adresu URL to przede wszystkim ciąg znaków. Może obejmować:
2; Litery łacińskie.
2; Cyfry arabskie (0-9).
2; Znaki zastrzeżone („+”, „=”, „!” i inne).
2; Znaki specjalne – przyjrzymy się im bardziej szczegółowo.
Używanie znaków specjalnych w adresach URL
Oczywiście takich nadmiernie „specjalnych” znaków nie używa się w adresach URL. Ale jest kilka:
- ?
- – służy do wydzielenia bloku z przesyłanymi parametrami w linii żądania;
- & - oddziela od siebie przekazywane parametry;
- = — oddziela zmienną w parametrze od jej wartości;
- : - służy do oddzielenia protokołu od reszty adresu URL;
- # - symbol jest używany w lokalnej części adresu. Umożliwia dostęp do określonej części żądanej strony;
Ale to wszystko jest tylko teorią. Zanim więc nauczymy się reszty, spójrzmy na mały praktyczny przykład.
Dobry przykład
Dla jasności weźmy ten prosty formularz rejestracyjny:
Oto jego kod:
Formularz rejestracyjny
W pierwszej linii na początku formularza podaliśmy dla niego plik obsługi (php) oraz sposób przesyłania danych poprzez adres URL serwera:
Oto kod pliku obsługi (1.php):
Twój nick:.$_GET["nick"]."
"; echo "
Twój wiek:”.$_GET["wiek"]."
";
?>
Wprowadzimy dane do formularza i wyślemy je na serwer do przetworzenia. Oto, co otrzymujemy na końcu:
Zwróć uwagę na format adresu URL w pasku adresu na pierwszym zrzucie ekranu. Po wprowadzeniu danych i kliknięciu przycisku „Prześlij dane” wartości wszystkich pól zostają przesłane na serwer w celu przetworzenia. I zostajemy przekierowani na stronę 1.php, gdzie znajduje się kod obsługi.
Zanim spojrzysz na wynik przetwarzania, spójrz na pasek adresu na drugim obrazku. Wyświetla wartości pól przekazanych do przetwarzania metodą GET.
W celu ukrycia danych przesyłanych do serwera wykorzystuje się je Metoda POST. Następnie powyższy adres URL będzie wyglądał następująco:
http://localhost/home/1.php.
Format adresów URL na stronach internetowych
Najczęściej strony internetowe korzystają z drzewiastego systemu adresów URL. Oznacza to, że prawidłowy adres URL składa się z kilku zagnieżdżonych elementów, z których ostatnim jest żądana strona internetowa.
Dla jasności weźmy konkretny adres URL, będący jedną z gałęzi adresu naszej witryny:
https://www..html
Rozłóżmy to kawałek po kawałku:
- www.site – ta część jest nazwa domeny strona. Jeśli wpiszesz go w pasku adresu przeglądarki, zostaniesz przeniesiony na stronę główną serwisu. W większości przypadków to plik indeksu. HTML;
- szablony – ta część adresu wskazuje na konkretną sekcję serwisu. W naszym przypadku jest to sekcja szablonów;
- strona_2.html – jest końcowym elementem adresu URL prowadzącym do strony internetowej sekcji tematycznej zasobu.
Najczęściej adresy URL głównych sekcji w pełni wyświetlają mapę witryny. Jednak nie wszystko jest takie proste z przekierowaniami na stronach wdrażanych w oparciu o popularne silniki (CMS).
Funkcje konstrukcji adresu URL w WordPress
W WordPressie, jak w każdym silniku zbudowanym w oparciu o PHP, wszystkie strony serwisu generowane są dynamicznie. Oznacza to, że jedna część jest pobierana z jednego szablonu, druga jest generowana „w locie” na podstawie kilku... Ale taka zmienność ma jedną istotną wadę - obecność fragmentów przekazanych parametrów w adresie URL.
Co więcej, narusza to nie tylko estetykę wyświetlania adresu, ale jest również niejednoznacznie odbierane przez wyszukiwarki. A to może negatywnie wpłynąć na promocję witryny:
Dlatego lepiej używać czystych adresów URL w swojej witrynie. Tylko skąd je zdobyć, skoro system CMS nie daje możliwości ich edycji?
Czyste adresy URL to adresy, które nie zawierają przekazanych parametrów (w przypadku WordPressa elementów zapytania do bazy danych), a jedynie ścieżkę do dokumentu. Oznacza to, że https://www..html jest przykładem czystego adresu URL.
Najłatwiejszym sposobem dostosowania wyświetlania adresu URL w WordPressie jest użycie specjalistycznych wtyczek.
Spory w tej kwestii - jak poprawnie napisać adres URL, z ukośnikiem na końcu czy bez? - były i będą. Argumenty są różnorodne i często sprzeczne. A kary za nieprawidłowy wpis w Universal Resource Locator (URL) powinny być dwojakiego rodzaju. Ze strony wyszukiwarek są to rzekomo kary za zduplikowane strony. Z punktu widzenia wydajności jest to rzekomo niepotrzebne przekierowanie na właściwą stronę z postami, automatycznie generowane przez serwer.
Jednak analizując specyfikacje techniczne Standardy internetowe, w szczególności dokument „RFC 1738 – Uniform Resource Locators (URL)”, trzeba przyznać, że obie możliwości zapisania adresu zasobu sieciowego są formalnie poprawne, a sankcja za skorzystanie z tej czy innej opcji to nic więcej niż osobliwość wyszukiwarka lub opowieści o ludziach pseudo-SEO.
Z punktu widzenia zwięzłości opcja bez ukośnika na końcu wydaje się bardziej poprawna, niezależnie od tego, czy Twój link kieruje do „pliku” na serwerze, czy do „folderu”, czego pośredni dowód zostanie pokazany poniżej. Ale w dokumencie nie ma ani jednego stwierdzenia, że inna opcja jest niepoprawna lub odnosi się do zupełnie innego zasobu.
Nie będę Was zanudzać wielostronicowym tłumaczeniem wspomnianego RFC, gdyż po pierwsze celem pytania były ukośniki na końcu adresu URL, a po drugie publikacja skierowana jest do zwykłych użytkowników silników, m.in. tych, których nie interesują wszystkie szczegóły, czekają krótkie wyjaśnienia i merytoryczne dowody.
W związku z tym przytoczę fragmenty tego dokumentu jako dowód i wyjaśnię. Każdy, kto nie jest tym zainteresowany, może od razu zapoznać się z konkluzją na końcu artykułu.
Ogólna składnia adresu URL
Przede wszystkim zwrócę uwagę na fragment z paragrafu 2. Ogólna składnia adresu URL (ogólna składnia adresu URL). W każdym przypadku udostępnię fragment tekstu w języku oryginalnym, a następnie tłumaczenie na język rosyjski.
Adresy URL służą do „lokalizacji” zasobów poprzez zapewnienie abstrakcyjnej identyfikacji lokalizacji zasobu. Adresy URL służą do „lokalizacji” zasobów poprzez zapewnienie abstrakcyjnej identyfikacji lokalizacji zasobu.
Oznacza to, że sam adres URL jest czystą abstrakcją. To, że może wydawać się zewnętrznie podobna do nazwy pliku lub folderu, wcale nie oznacza, że jest to fizyczne odniesienie do właśnie takiego a takiego pliku, a nie jakiegoś innego w przestrzeni plików serwera. Zostanie to wyraźnie określone poniżej w dokumencie. Notatka
- Ogólnie rzecz biorąc, w odniesieniu do linków http zasadniczo błędne jest twierdzenie, że np. http://domena.com/ścieżka/podścieżka/nazwa pliku.txt
- - rzekomo wskazuje na plik http://domena.com/ścieżka/podścieżka/
- - rzekomo wskazuje na folder
http://domain.com/path - rzekomo błędnie wskazuje folder
Po prostu przywykliśmy to mówić, ponieważ wygodnie jest kojarzyć linki z plikami w witrynie. W rzeczywistości wszystkie te linki wskazują na jakiś rodzaj zasobu, nie wskazując w żaden sposób jego rodzaju. To, co kryje się za każdym zasobem, czyli jaki rodzaj prawdziwego pliku lub folderu i jaki rodzaj treści będzie udostępniany za pośrednictwem takiego łącza, zależy już od konfiguracji serwera.
Ważne jest, aby zrozumieć, że w linkach nie ma czegoś takiego jak „plik”, „folder”, „podfolder”, „tekst”, „obraz”, „html”, „skrypt”, „arkusz stylów” i tak dalej. Brak ukośnika na końcu lub jego brak nie oznacza absolutnie nic, dopóki link nie przejdzie transformacji wewnątrz serwera i to on nie zadecyduje, dokąd faktycznie prowadzi link i jaki rodzaj treści się za nim kryje. Tylko ta decyzja dotyczy wewnętrznej architektury serwera.
Schematy hierarchiczne
Niektóre schematy adresów URL (takie jak schematy ftp, http i pliki) zawierają nazwy, które można uznać za hierarchiczne; składniki hierarchii są oddzielone znakiem „/”.
Niektóre schematy adresów URL (takie jak ftp, http i plik) zawierają nazwy, które można uznać za hierarchiczne; Elementy hierarchii oddzielane są znakiem „/”.
Oznacza to, że w niektórych schematach adresów zawartość lokalizatora zasobów nie może być sugerowana jako hierarchiczna i nie zostało jeszcze zastrzeżone, że hierarchia jest równoważna jakiejkolwiek formie, powiedzmy, plikowej.
Ogólna składnia diagramu sieciowego
//:@:/Poniżej znajduje się wyciąg z punktu 3.1. :@", ":",
":Składnia wspólnego schematu internetowego (wspólna składnia schematu sieciowego). Niektóre lub wszystkie części” :@", ":",
":", I "/ " może zostać wykluczone. Niektóre lub wszystkie części "
Oznacza to, że sam adres URL jest czystą abstrakcją. To, że może wydawać się zewnętrznie podobna do nazwy pliku lub folderu, wcale nie oznacza, że jest to fizyczne odniesienie do właśnie takiego a takiego pliku, a nie jakiegoś innego w przestrzeni plików serwera. Zostanie to wyraźnie określone poniżej w dokumencie." I "/
"można wykluczyć. To, nawiasem mówiąc, jest odpowiedź na pytanie wywodzące się z tego, które rozważamy. Często toczy się debata na ten temat: jaki jest właściwy sposób podania linku do domeny (hosta) – bez ukośnika na końcu czy z ukośnikiem?
Jak to zrobić dobrze
http://domena.com/ lub http://domena.com?
I tak i tak jest poprawne. Tyle, że pierwszy ukośnik po nazwie hosta ma na celu oddzielenie ścieżki od nazwy hosta.
Ten sam akapit dokumentu informuje o tym w następujący sposób:Ścieżka adresu URL Pozostała część lokalizatora składa się z danych specyficznych dla schematu i jest nazywana „ścieżką adresu URL”. Dostarcza szczegółowych informacji o sposobie dostępu do określonego zasobu. Zauważ, że znak „/” pomiędzy hostem (lub portem) a ścieżką adresu URL NIE jest częścią ścieżki adresu URL.
Pozostała część lokalizatora składa się z danych specyficznych dla schematu i jest nazywana „ścieżką adresu URL”. Zawiera szczegółowe informacje na temat sposobu dostępu do określonego zasobu.
Należy pamiętać, że znak „/” pomiędzy hostem (lub portem) a ścieżką URL nie jest częścią ścieżki adresu URL.
Nie ma słowa, które zobowiązywałoby Cię do umieszczenia tego znaku na końcu lub nie, gdy ścieżka adresu URL jest równa pustemu ciągowi znaków (jak wielu z nas powiedziałoby, gdy adres URL prowadzi do katalogu głównego witryny). Nikt nie ma prawa nakładać na Ciebie kar „za dwa ujęcia strony głównej”, bo zgodnie ze specyfikacją w obu przypadkach linkujesz URL do tego samego zasobu.
W przypadku niektórych systemów plików znak „/” używany do określenia hierarchicznej struktury adresu URL odpowiada ogranicznikowi używanemu do konstruowania hierarchii nazw plików, dzięki czemu nazwa pliku będzie wyglądać podobnie do ścieżki adresu URL. NIE oznacza to, że adres URL jest nazwą pliku uniksowego.
Znak „/” służy do wskazania hierarchicznej struktury adresu URL, odpowiadającej ogranicznikowi używanemu przy konstruowaniu hierarchii nazw plików, dlatego w niektórych systemach plików nazwa pliku wygląda podobnie do ścieżki adresu URL. Nie oznacza to jednak, że adres URL jest nazwą pliku w stylu uniksowym. Pomimo faktu, że ten akapit dotyczy schematu ftp, jego stwierdzenia mają jednak zastosowanie do innych schematów (http, gopher, prospero i tak dalej). Tylko w schemacie pliku symbol ukośnika logicznie oznacza to samo, co na przykład w nazwach plików.
plik://serwer_lub_urządzenie/ścieżka/podścieżka/nazwa pliku.txt
Http :/?Adres URL HTTP ma postać: http:// Gdzie I Są zgodne z opisem w Sekcji 3.1. Jeśli: Jest pominięty, domyślny port to 80. Żadna nazwa użytkownika ani hasło nie są dozwolone. Jest selektorem HTTP i jest ciągiem zapytania. The Jest opcjonalny, podobnie jak i poprzedzające go „?”. Jeśli żadne Ani jest obecny, znak „/” można również pominąć. W ramach :/?I komponenty, „/”, „;”, „?” są zastrzeżone. Znak „/” może być używany w protokole HTTP do oznaczenia struktury hierarchicznej. Adres URL schematu http ma postać: http:// Gdzie I To samo, co opisano w paragrafie 3.1. Jeśli: Pominięto, przyjmuje się, że domyślny port to 80. Nazwa użytkownika lub hasło jest nieprawidłowe. To jest selektor HTTP i - ciąg zapytania. Jest opcjonalny, tak jak jest wraz z poprzedzającym znakiem „?”. W przeciwnym razie
Oznacza to, że sam adres URL jest czystą abstrakcją. To, że może wydawać się zewnętrznie podobna do nazwy pliku lub folderu, wcale nie oznacza, że jest to fizyczne odniesienie do właśnie takiego a takiego pliku, a nie jakiegoś innego w przestrzeni plików serwera. Zostanie to wyraźnie określone poniżej w dokumencie.Żaden nie występują, znak „/” można również pominąć. W elementach
I
znaki „/”, „;”, „?” są zastrzeżone. Znaku „/” można używać w protokole HTTP do definiowania struktury hierarchicznej.
Stwierdza również, że można określić łącze bez końcowego ukośnika. W w tym przypadku Mówiliśmy o sytuacji, gdy ścieżka łącza jest pusta – wskazuje na katalog główny hosta.
Wpis formalny I na koniec fragment z paragrafu 5. BNF dla określonych schematów URL (notacja formalna dla określonych schematów URL).= hsegment *[ "/" hsegment ] hsegment = *[ uchar | „;” | ":" | „@” | „&” | "=" ] szukaj = *[ uchar | „;” | ":" | „@” | „&” | "=" ] ... ... lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" |
"ja" | "j" | "k" | "ja" | "m" | "n" | "o" | "p" |
"q" | "r" | „s” | „t” | „ty” | "v" | "w" | "x" |
"y" | „z” hialfa = „A” | "B" | „C” | „D” | „E” | „F” | "G" | „H” | „Ja” | "J" | „K” | „L” | „M” | „N” | „O” | „P” | „P” | „R” |„S” | „T” | „Ty” | „V” | „W” | „X” | „T” | „Z” alfa = niska alfa | cyfra hialpha = „0” | „1” | „2” | „3” | „4” | „5” | „6” | „7” |
„8” | „9” sejf = „$” | „-” | „_” | „.” | „+” dodatkowo = „!” | „*” | """ | "(" | ")" | "," szesnastkowo = cyfra | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" |. "c" |. "e" |. "%" szesnastkowy niezarezerwowany |
- Zwróć uwagę, jak dokładnie element hpath - ścieżka łącza - jest tworzony zgodnie z regułami. Elementy ścieżki hsegmentu – segmenty – oddzielone są ukośnikiem.
- Jakby sugerując ważną ideę, że ukośnik dzieli ścieżkę na hierarchiczne części i zawsze znajduje się wewnątrz. W zasadzie może się zdarzyć, że ostatnim elementem hsegmentu będzie pusty ciąg znaków (wynika to z jego definicji), po czym mimowolnie na końcu adresu URL pojawi się ukośnik zamykający.
Wniosek Podział ścieżki na segmenty za pomocą ukośnika oznacza obecność niepustych nazw tych segmentów. W związku z tym link zakończony ukośnikiem wydaje się nielogiczny (choć nie jest zabroniony) w tym sensie, że zdaje się wskazywać na jakiś ostatni odcinek ścieżki, ale w żaden sposób nie nazywa tego odcinka. Podobnie jak link jest nielogiczny (ale też nie zabroniony)
- http://domain.com/level1////levelX
- , który nie nazywa pośrednich segmentów ścieżki, jeśli ścieżkę traktuje się nie jako zbiór parametrów, ale jako strukturę hierarchiczną.
W języku potocznym treść semantyczną obu linków można wyjaśnić w następujący sposób:
- - adresy do domyślnego punktu początkowego drugiego poziomu hierarchii
- - adresuje do bliżej nieokreślonego punktu w ramach drugiego poziomu hierarchii, czyli tak jakby serwerowi powierzono zadanie, że „wchodzimy na drugi poziom hierarchii, a ty sam ustalasz, w którym punkcie tego poziomu się znajdujesz uważać za domyślny początkowy.”
kieruj gościa na drugi poziom hierarchii zasobów. A to, że dany serwer może na swój sposób zinterpretować ukośnik na końcu i zacząć wewnętrznie przekierowywać do domyślnego punktu początkowego poziomu - powiedzmy do pliku Index.html, to już jest szczególny przypadek konkretnego konfiguracja. Podobnie jak przy implementacji systemu URL czytelnego dla człowieka, wszystkie rekordy przekierowań korzystające z modułu serwera mod_rewrite definiują własną (wrodzoną w konkretnym silniku) koncepcję hierarchicznej struktury URL, w której elementy ścieżki można przyrównać do parametrów zapytania i mieć nic wspólnego ze strukturą plików witryny (klasyczny przykład: http://domain.com/ru/path, element ru jest parametrem bieżącego języka, a nie folderem na stronie).
Szczególnie chciałbym podkreślić, że jest to wewnętrzna wiedza serwera, zdeterminowana jego konfiguracją, a także silnikiem zainstalowanym na stronie. Usługa zewnętrzna, powiedzmy ta sama wyszukiwarka, nie może snuć domysłów i nie ma pojęcia, czy i jak linki z ukośnikami i bez ukośników różnią się, chyba że serwer witryny jest specjalnie skonfigurowany tak, aby takie linki dostarczały innej treści.
Dla Twojej wiadomości
Na poziomie realizacji kwestia ukośników na końcach nie ma zasadniczego znaczenia, co potwierdza wiele znanych portali. W niektórych przypadkach wszystkie linki kończą się ukośnikiem, w innych – bez ukośnika. Najważniejsze jest to, że treść linków nie okazuje się inna, a dla Yandex musisz zarejestrować przekierowanie 301 z tych linków, których nie używasz (powiedzmy kończących się ukośnikiem) do tych, których używasz. Faktem jest, że według niepotwierdzonych oświadczeń serwisu wsparcia Yandex, ta wyszukiwarka może rzekomo popełniać błędy, a nie „sklejać” (zapamiętywać w swojej wiedzy) lub z pewnym opóźnieniem sklejać adresy z ukośnikiem bez ukośnika w jeden.

Oto przykład implementacji takiego przekierowania przy użyciu głównego pliku .htaccess:
# jeśli wejściowy adres URL kończy się ukośnikiem (em, ami), # ustaw 301. przekierowanie na stronę bez ukośnika RewriteCond %(REQUEST_URI) ^/.+/$ RewriteRule ^(.*?)/+$ http:/ /%(HOST_HTTP)/$1
Dla Google (znowu według informacji niepotwierdzonych eksperymentem) te przekierowania nie są istotne, ponieważ rzekomo wie, jak poprawnie i bez przekierowań przykleić takie adresy.
Pamiętać Jest wiele osób, które uważają się za specjalistów SEO.
Ale nie każdy z nich taki jest. Co więcej, temat SEO często jest spekulowany bez odpowiedniej wiedzy i podstaw, po prostu w przekonaniu, że ty też jesteś ignorantem w tej dziedzinie, więc łatwo uwierzysz w jakiekolwiek „makaron”. Kiedy dowiesz się, że jedna z Twoich stron „wyleciała z indeksu”, skorzystaj z bardzo dobrej rekomendacji Yandex: O ewentualnych błędach indeksowania możesz dowiedzieć się w serwisie Yandex.Webmaster. W tej usłudze zawsze możesz zobaczyć listę swoich stron, które są w wyszukiwaniu, oraz listę stron wykluczonych z wyszukiwania z jakiegoś powodu. Google ma również podobną usługę. Zaufaj tej wiedzy, a nie opiniom pseudoekspertów, którzy gdzieś coś słyszeli kącikiem uszu i na tej podstawie rekomenduj Ci zrobienie tego, co wydaje im się jedyną słuszną rzeczą. Tutaj Bardzo ciekawa publikacja Little-Known SEO Facts, opublikowana w kwietniu 2017 roku. Istnieje duże badanie z wieloma zrzutami ekranu, które rozpoczęło się od sprawdzenia słuszności kilku popularnych orzeczeń w tej dziedzinie promocja w wyszukiwarkach i używaj jasnych przykładów, aby przekazać wyniki przeciętnemu właścicielowi witryny. To samo badanie ukazuje jednocześnie młodemu czytelnikowi szereg oczywistych, zwyczajnych i raczej niepozornych, a jednak zadziwiających cech organicznych wyników wyszukiwania.
Ale nie każdy z nich taki jest. Co więcej, temat SEO często jest spekulowany bez odpowiedniej wiedzy i podstaw, po prostu w przekonaniu, że ty też jesteś ignorantem w tej dziedzinie, więc łatwo uwierzysz w jakiekolwiek „makaron”. Kiedy dowiesz się, że jedna z Twoich stron „wyleciała z indeksu”, skorzystaj z bardzo dobrej rekomendacji Yandex: O ewentualnych błędach indeksowania możesz dowiedzieć się w serwisie Yandex.Webmaster. Wyszukiwania w Google i Yandex. oraz kontekstowa sieć mediów Yandex i Google.
Aby uzyskać maksymalną ekspozycję w indeksie wyszukiwania lokalnego, są gotowi wydać pieniądze na kilka tekstów SEO naraz, aby wypromować swój billboard, co pachnie całkiem sporymi pieniędzmi. Sądząc po plotkach, zamówienia na 30 kilogramów rubli prześlizgują się, a ponieważ chłopaki zlecają je partnerom SEO, tutaj możesz budować mosty partnerskie i uzyskać dobry dodatkowy dochód. Według różnych źródeł od 50 do 95% wszystkich e-maili na świecie to spam od cyberoszustów. Cele wysyłania takich listów są proste: zainfekowanie komputera odbiorcy wirusem, kradzież haseł użytkowników, zmuszenie osoby do przekazania pieniędzy „na cele charytatywne”, wprowadzenie danych osobowych
karta bankowa
lub wyślij skany dokumentów.
Często spam jest irytujący na pierwszy rzut oka: krzywy układ, automatycznie przetłumaczony tekst, formularze do wpisania hasła bezpośrednio w temacie listu. Istnieją jednak złośliwe listy, które wyglądają przyzwoicie, subtelnie grają na ludzkich emocjach i nie budzą wątpliwości co do ich prawdziwości.



W artykule omówiono 4 rodzaje fałszywych listów, na które Rosjanie najczęściej się nabierają.
1. Listy „organizacji rządowych” Oszuści mogą podszywać się pod urząd skarbowy, fundusz emerytalny, Rospotrebnadzor, stację sanitarno-epidemiologiczną i inne organizacje rządowe. Dla wiarygodności do listu dołączono znaki wodne, skany pieczęci i symboli państwowych. Najczęściej zadaniem przestępców jest zastraszenie osoby i nakłonienie jej do otwarcia pliku z dołączonym wirusem. Zwykle jest to program szyfrujący lub blokujący system Windows, który wyłącza komputer i wymaga wysłania
płatne SMS-y
wznowić pracę. Złośliwy plik można zamaskować jako nakaz sądowy lub wezwanie do stawienia się przed szefem organizacji.
Strach i ciekawość wyłączają świadomość użytkownika. Fora księgowe opisują przypadki, w których pracownicy organizacji przynieśli na swoje domowe komputery pliki z wirusami, ponieważ ze względu na program antywirusowy nie mogli ich otworzyć w biurze. Czasami oszuści proszą Cię w odpowiedzi na list o przesłanie dokumentów w celu zebrania informacji o firmie, które będą przydatne w innych oszustwach. W zeszłym roku jednej grupie oszustów udało się oszukać wiele osób, stosując sztuczkę odwracającą uwagę od „prośby o przesłanie dokumentów faksem”. Kiedy księgowy lub menadżer to przeczytał, od razu przeklął urząd skarbowy: „Tam siedzą mamuty, o mój Boże!” i przeniosłem myśli z samego listu na rozwiązanie
problemy techniczne


Blokery systemu Windows i oprogramowanie ransomware mogą ukrywać się w fałszywych listach nie tylko od organizacji rządowych, ale także przed bankami. Komunikaty „Zaciągnięto pożyczkę na Twoje nazwisko, prosimy o zapoznanie się z pozwem” mogą naprawdę przestraszyć i sprawić, że będziesz chciał otworzyć plik.
Można też nakłonić osobę do wpisania fałszywki konto osobiste, oferując zobaczenie naliczonych bonusów lub otrzymanie nagrody, którą wygrał w loterii Sbierbanku.
Rzadziej oszuści wysyłają faktury za opłacenie opłat za usługi i dodatkowe odsetki od pożyczki na 50-200 rubli, które łatwiej zapłacić niż zrozumieć.
3. Listy od „współpracowników”/„partnerów”

Niektórzy dostają dziesiątki listy biznesowe z dokumentami w ciągu dnia pracy. Przy takim obciążeniu łatwo dać się nabrać na tag „Re:” w temacie listu i zapomnieć, że jeszcze z tą osobą nie korespondowałeś.
Zwłaszcza jeśli pole truciciela wskazuje „Aleksander Iwanow”, „Ekaterina Smirnova” lub inne proste rosyjskie imię, które absolutnie nie zapada w pamięć osoby stale pracującej z ludźmi.
Jeśli celem oszustów nie jest pobieranie płatności SMS za odblokowanie systemu Windows, ale wyrządzenie szkody konkretnej firmie, wówczas w imieniu prawdziwych pracowników można wysyłać listy zawierające wirusy i linki phishingowe. Listę pracowników można gromadzić w sieciach społecznościowych lub przeglądać na stronie internetowej firmy.
Jeśli ktoś zobaczy w skrzynce pocztowej list od osoby z sąsiedniego działu, to nie przyjrzy się mu bliżej, może nawet zignorować ostrzeżenia antywirusa i mimo wszystko otworzyć plik.
4. Listy z „Google/Yandex/Mail”
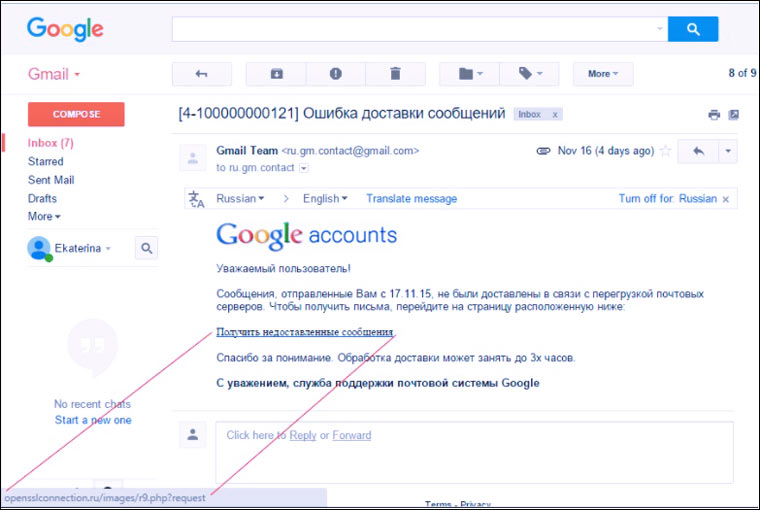

Google czasami wysyła e-maile do właścicieli Skrzynki pocztowe Gmailaże ktoś próbował zalogować się na Twoje konto lub że zabrakło Ci miejsca na Dysku Google. Oszuści skutecznie je kopiują i zmuszają użytkowników do wprowadzania haseł na fałszywych stronach.
Użytkownicy Yandex.Mail, Mail.ru i innych usług pocztowych otrzymują również fałszywe listy od „administracji usługi”. Standardowe legendy to: „Twój adres został dodany do czarnej listy”, „Twoje hasło wygasło”, „Wszystkie e-maile z Twojego adresu zostaną dodane do folderu spam”, „Sprawdź listę niedostarczonych e-maili”. Podobnie jak w poprzednich trzech punktach, główną bronią przestępców jest strach i ciekawość użytkowników.
Jak się chronić?

Zainstaluj program antywirusowy na wszystkich swoich urządzeniach, aby automatycznie blokował złośliwe pliki. Jeśli z jakiegoś powodu nie chcesz z niego korzystać, sprawdź wszystko, co jest choć trochę podejrzane załączniki do poczty NA wirustotal.com
Nigdy nie wprowadzaj haseł ręcznie. Używaj menedżerów haseł na wszystkich urządzeniach. Nigdy nie oferują opcji hasła do wejścia na fałszywych stronach. Jeśli z jakiegoś powodu nie chcesz z nich korzystać, wpisz ręcznie adres URL strony, na której będziesz wprowadzał hasło. Dotyczy to wszystkich systemów operacyjnych.
Tam, gdzie to możliwe, włącz potwierdzanie hasła za pomocą wiadomości SMS lub identyfikacji dwuskładnikowej. I oczywiście warto pamiętać, że nie można przesyłać skanów dokumentów, danych paszportowych ani przekazywać pieniędzy obcym osobom.
Być może wielu czytelników, patrząc na zrzuty ekranu listów, pomyślało: „Czy jestem głupcem, otwierając pliki z takich listów? Z kilometra widać, że to pułapka. Nie będę zawracał sobie głowy menedżerem haseł i uwierzytelnianiem dwuskładnikowym. Po prostu będę ostrożny.
Tak, większość fałszywych e-maili można wykryć wzrokowo. Nie dotyczy to jednak przypadków, gdy atak jest skierowany specjalnie przeciwko Tobie.
Najbardziej niebezpieczny spam ma charakter osobisty

Jeśli zazdrosna żona chce czytać pocztę męża, Google zaoferuje jej dziesiątki witryn oferujących usługę „Hakowanie poczty i profili w sieciach społecznościowych bez przedpłaty”.
Schemat ich działania jest prosty: wysyłają do osoby wysokiej jakości listy phishingowe, które są starannie skomponowane, starannie ułożone i uwzględniają cechy osobiste danej osoby. Tacy oszuści szczerze próbują złapać konkretną ofiarę. Od klienta dowiadują się o jego kręgu towarzyskim, upodobaniach i słabościach. Opracowanie ataku na konkretną osobę może zająć godzinę lub dłużej, ale wysiłek się opłaca.
Jeśli ofiara zostanie złapana, wysyła klientowi zrzut ekranu skrzynki pocztowej i prosi o zapłatę (średnia cena wynosi około 100 dolarów) za swoje usługi. Po otrzymaniu pieniędzy wysyłają hasło do skrzynki pocztowej lub archiwum ze wszystkimi listami.
Często zdarza się, że gdy ktoś otrzymuje od brata list z linkiem do pliku „Dowody kompromitujące wideo dotyczące Tanyi Kotowej” (ukryty keylogger), ogarnia go ciekawość. Jeśli do listu dołączona zostanie treść zawierająca szczegóły znane wąskiemu kręgowi osób, wówczas osoba ta natychmiast zaprzecza możliwości, że jego brat mógł zostać zhakowany lub że ktoś inny podszywa się pod niego. Ofiara relaksuje się i wyłącza program antywirusowy do cholery, aby otworzyć plik.
Z takich usług mogą skorzystać nie tylko zazdrosne żony, ale także pozbawieni skrupułów konkurenci. W takich przypadkach cena jest wyższa, a metody bardziej subtelne.
Nie powinieneś polegać na swojej uważności i zdrowym rozsądku. Pozwól, aby na wszelki wypadek chronił Cię pozbawiony emocji program antywirusowy i menedżer haseł.
P.S. Dlaczego spamerzy piszą takie „głupie” listy?
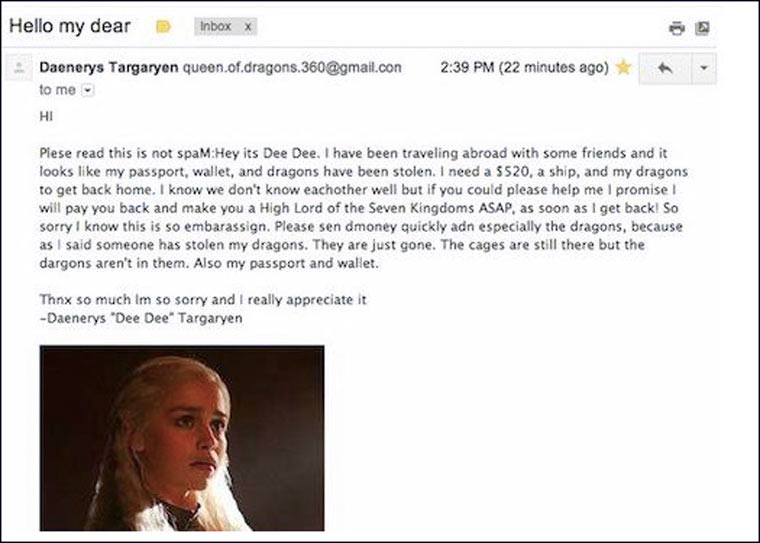
Starannie przygotowane fałszywe e-maile są stosunkowo rzadkie. Jeśli pójdziesz do folderu ze spamem, możesz się dobrze bawić. Jakie postacie wymyślają oszuści, aby wyłudzić pieniądze: dyrektor FBI, bohaterka serialu „Gra o tron”, jasnowidz, który został do Ciebie wysłany przez siły wyższe i chce zdradzić Ci sekret Twojej przyszłości za 15 dolarów zabójca, któremu nakazano zapłacić, ale szczerze oferuje spłatę.
Mnóstwo wykrzykników, przyciski w treści listu, dziwny adres nadawcy, bezimienne powitanie, automatyczne tłumaczenie, rażące błędy w tekście, wyraźny przerost kreatywności - listy w folderze spamu po prostu „krzyczą” o swojej ciemności pochodzenie.
Dlaczego oszuści, którzy wysyłają swoje wiadomości do milionów odbiorców, nie chcą spędzić kilku godzin na pisaniu schludnego listu i wydać 20 dolarów na tłumacza, aby zwiększyć reakcję odbiorców?
W badaniu Microsoftu Dlaczego nigeryjscy oszuści podają, że pochodzą z Nigerii? dogłębnie przeanalizowano pytanie „Dlaczego oszuści w dalszym ciągu wysyłają listy w imieniu miliarderów z Nigerii, skoro opinia publiczna wiedziała o „listach nigeryjskich” od 20 lat”. Według statystyk ponad 99,99% odbiorców ignoruje taki spam.
: Zawsze chciałem to zrozumieć, ale jego znaczenie było tak małe, że zawsze znajdował się powód, aby tego nie robić :)
Czy zastanawiałeś się kiedyś: Adres URL – co to jest?
Zawsze się z tym spotykam, ale do tej pory nie chciałem rozumieć, jaka jest różnica między terminami URI, URL, URN, a potem nagle postem (niestety, to już odeszło w zapomnienie), zdecydowałem - ja' Sam to przeczytam i opowiem innym, chociaż, jak napisano powyżej, nic się w tej kwestii nie zmieni, ale czasami lubię używać liter, więc przeczytaj rozsądne tłumaczenie:
Czy zauważyłeś kiedyś pasek adresu w przeglądarce? Co to jest? URI, URL czy URN? Wielu z nas nie rozróżnia URI, URL, URN, a niektórzy nawet nie słyszeli o terminach URI i URN, wszyscy po prostu używają terminu URL. Spróbujmy to wspólnie rozwiązać.
Dekodowanie skrótów
URI – jednolity identyfikator zasobu identyfikator ratunek)
Adres URL — jednolity lokalizator zasobów (ujednolicony lokalizator lokalizacji ratunek)
URN — jednolita nazwa zasobu Nazwa ratunek)
Uwaga, prawda kryje się tutaj w szczegółach, ale na razie nic nie jest jasne, panuje jakiś bałagan. Przejdźmy dalej.
Definicja
URI: Oznacza nazwę i adres zasobu w sieci. Z reguły dzieli się go na URL i URN, więc URL i URN są składnikami URI.
URL: Adres jakiegoś zasobu w Internecie. Adres URL określa lokalizację zasobu i sposób, w jaki można uzyskać do niego dostęp.
URN: nazwa jakiegoś zasobu w sieci. Znaczenie URN polega na tym, że definiuje on jedynie nazwę konkretnego przedmiotu, który można znaleźć w wielu określonych miejscach.
Nie ma nic lepszego niż konkretny przykład
URI = http://site/2009/09/uri-url-urn.html
Adres URL = http://strona
URN = /2009/09/uri-url-urn.html
Podsumujmy to
URI to koncepcja abstrakcyjnego identyfikatora, podczas gdy URL i URN to konkretna implementacja adresu i nazwy.
Mam nadzieję, że wszystko jest dla wszystkich jasne. Bądź piśmienny!
Postrzeganie każdego z nas jest indywidualne, więc dyskutuj i czytaj dyskusje w komentarzach do artykułu, jest tam wiele ciekawych rzeczy.









